ВОПРОСЫ ДЛЯ ЗАЧЕТА (С ОТВЕТАМИ) ПО ДИСЦИПЛИНЕ «СОВРЕМЕННЫЕ КОМПЬЮТЕРНЫЕ ТЕХНОЛОГИИ В РЕКЛАМЕ И СВЯЗЯХ С ОБЩЕСТВЕННОСТЬЮ» для студентов 3-го курса
ПЕРЕЧЕНЬ
ВОПРОСОВ, ВЫНОСИМЫХ НА ЗАЧЕТ С ОЦЕНКОЙ ПО ДИСЦИПЛИНЕ
«СОВРЕМЕННЫЕ КОМПЬЮТЕРНЫЕ ТЕХНОЛОГИИ В РЕКЛАМЕ И СВЯЗЯХ С
ОБЩЕСТВЕННОСТЬЮ»
для студентов 3-го курса, обучающихся по направлению подготовки
42.03.01 Реклама и связи с общественностью
Состав отчета по исследовательскому проекту
(срок сдачи 17-24.12):
1. Титул (тема, ФИО), введение (задачи, характеристика выборки,
ссылка на онлайн-ресурс)
2. Анкета (оформленная в соответствии с требованиями)
3. Табличный отчет по базе данных + одномерное распределение
4. Краткие выводы по сформулированным задачам
5. Презентация с визуализацией данных и краткими выводами
Перечень теоретических вопросов:
1.
Направления исследовательской деятельности в рекламе и связях с
общественностью
2.
Современные компьютерные технологии и направления их
использования в исследовательской деятельности.
3.
Современные компьютерные технологии сбора данных.
4.
Требования к оформлению анкеты.
5.
Создание баз социологических данных в SPSS.
Каждая переменная
- это вопрос в анкете. В программе SPSS по умолчанию
установлены 10 основных характеристик, которыми может быть описана переменная:
name, type, width, decimals, label, values, missing, columns, align и measure. В принципе,
по значимости и важности заполнения эти переменные можно разделить на те,
которые относятся к параметрам определения переменной и те, которые отвечают за
удобство вывода.
Основные значения параметров переменной:
Name - имя переменной, которое будет отображаться в поле ввода. Это же имя
использует программа для идентификации переменной. Имя не должно превышать 8
символов и быть только на английском. (В более поздних версиях программы можно
использовать русский текст)
Type - определение типа переменной. Другими словами - какая информация вводится в
качестве значений: число, дата, случайное значение, запятая и т.п.[6] Чаще всего
используются форматы «числовой» (Nymeric), дата (Date) и строковый (текст, String). В
первом случае в качестве значения может приниматься любое число, во втором - дата в
определенном формате, в последнем - текст.

2
Width - длина переменной. Количество разрядов, которые могут уместиться в ячейке.
Decimals - число десятичных разрядов после запятой.
Label
- имя, метка, переменной для пользователя, более подробное описание
переменной. Обычно формулируется именно как сам вопрос анкеты. Используется в
отчетах и позволяет использовать любой шрифт.
Values - метки значений переменной, которые переменная может принимать. В SPSS
данные представлены преимущественно в числовом формате, т.к. текстовый формат не
поддается статистическому анализу. Например, пол, можно закодировать как
1
-
мужской, 0 - женский. При вводе значений очень важно соблюдать последовательность
при определении ранговой шкалы - значения должны идти по возрастанию. Чуть ниже
будет рассмотрен пример некорректного ввода данных. Для определения метрической
шкалы, значения можно не указывать.
Метки значений вводятся в дополнительном окне.
Рис.4. Определение типа переменной.

3
Measure - определение шкалы переменной. Scale - число, метрическая шкала; ordinal -
ранговая шкала; nominal - номинальная. Чрезвычайно важная характеристика, так как
именно от корректного выбора типа шкалы будет зависеть обработка. В программе
заложена графическая подсказка - пиктограмма напротив каждого типа шкалы (линейка -
как результат измерения - число; возрастающая гистограмма - определение ранга; круги
множеств - несравнимые характеристики, обозначающие непересекающиеся множества).
Missing
- определение пропущенных значений. Могут задаваться системой
автоматически (System-defined missing values) или пользователем (User-defined missing
values).
Columns - определение ширины столбца.
Align - выравнивание в ячейке (левый край, правый, центр).
6. Контроль и чистка данных в SPSS.
Чистку массива можно условно разделить на техническую и логическую. Техническая
чистка используется для: 1) проверки вопросов с множественными альтернативами:
контроль максимального / минимального количества выбранных вариантов ответа (на тот
случай если количество категорий, которые необходимо выбрать установлено точно или
ограничено определенным количеством); 2) проверка для вопросов этого же типа, не
выбран ли вариант «Ничего из перечисленного» вместе с другими вариантами ответа; 3)
правильных
переходов
после
вопросов-фильтров.
Логическая чистка - более творческая. Если в случае технической чистки исследователь
может руководствоваться исключительно требованиями к заполнению анкеты, то при
логической ему необходимо подключить свое воображение и знания с целью
определения тех конфигураций ответов, которые в логическом смысле являются
противоречивыми. Нахождение таких ситуаций обычно указывает на ошибки ввода
данных
или
фальсификацию
анкет.
В меню Analyze - команда Reports - Case Summaries (Отчеты - Сводка по данным) предназначена для
проверки состава и качества данных;
4
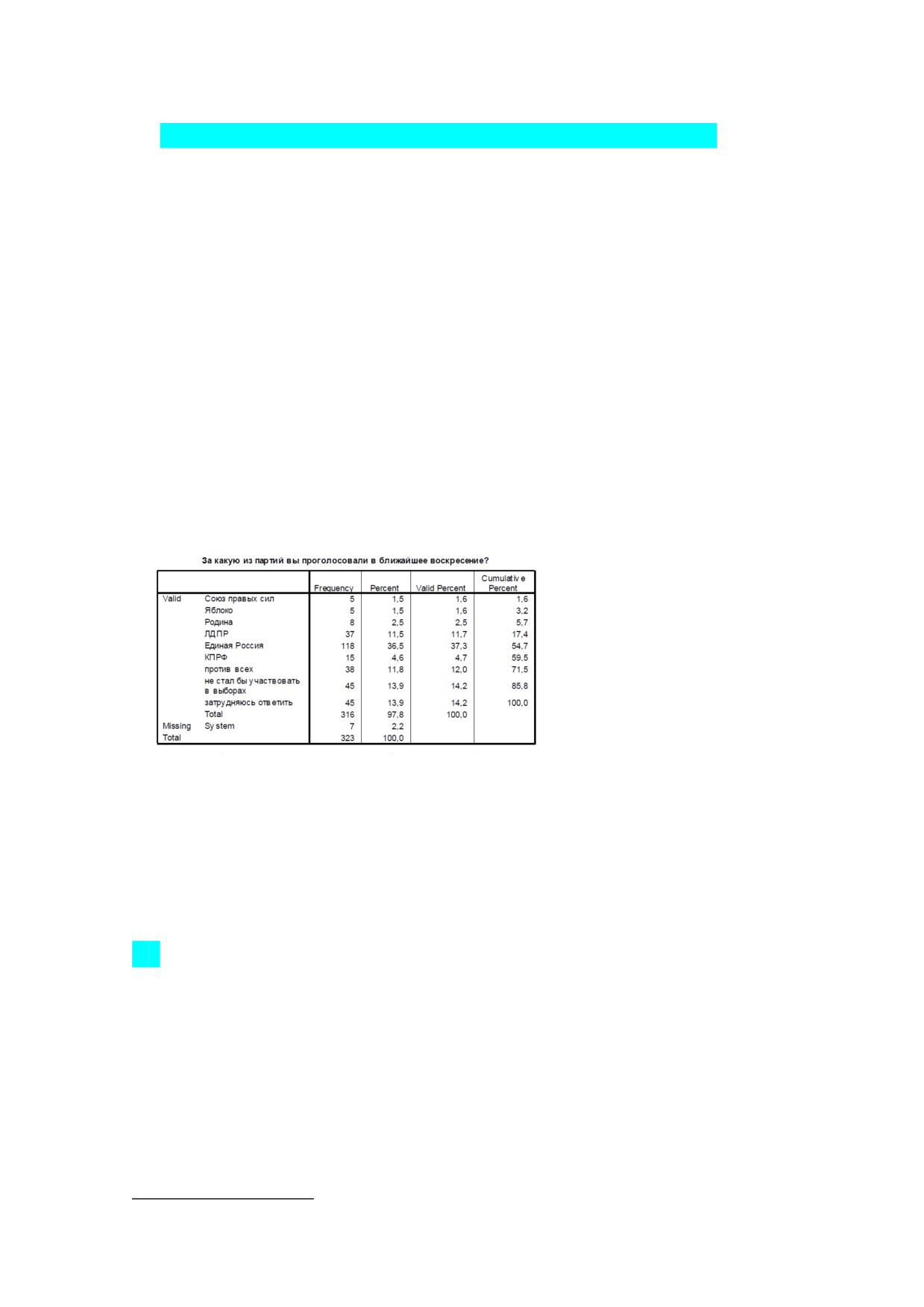
Создание отчета о данных с одномерным распределением.
Методы одномерного описательного анализа решают задачу сжатия исходной информации, ее
компактного представления. Как правило, в процессе исследования бывает важно получить совокупные
характеристики отдельных предметов через призму какого-либо конкретного свойства. Вместо большого
числа отдельных показателей нам требуется одно значение, которое было бы типичным
(репрезентативным) для всей совокупности объектов. Принадлежность к какой социальной или возрастной
группе наиболее типична для членов определенной партии? Сколько раз в среднем в месяц студенты
смотрят общественно-политические передачи? Ответы на эти вопросы дает анализ одномерных (частотных)
распределений, в частности подсчет средних величин для разных уровней измерения. Анализ одномерных
распределений позволяет заодно установить, насколько типичное значение в действительности типично,
репрезентативно по отношению к совокупности данных.
В одномерном описательном анализе используются методы:
Построения частотных распределений;
Графического представления поведения анализируемой переменной;
Получения статистических характеристик распределения анализируемой переменной.
1)Вначале считаем частоту.
Для создания частотных распределений в меню Analyze (Анализ) нужно выбрать команду Descriptve
Statstc (Описа-тельные статистики), затем Frequencies (Частоты). Появится диалоговое окно.
Переносим данные - готово)
Frequency (Частота) - число объектов, соответствующих каждой категории (градации) переменной (число
респондентов, выбравших соответствующий вариант ответа)
Percent (Процент) - процент от общей численности (с учетом пропусков). Если в файле есть пропу-
щенные значения, то их процент указан в предпоследней строке Missing System.
Valid percent (Валидный процент) - процент значений для каждой категории за вычетом пропущен- ных
значений.
Cumulatve percent (Кумулятивный процент) - накопленный процент величины Valid percent.
Valid (Валидные значения) - список градаций (значений) переменной.
Total (Итого) - итоговые значения.
7. Подытоживание (обработка) порядковых переменных в SPSS
На порядковом уровне измерения присутствует упорядочивание категорий с точки зрения
возрастания/убывания интенсивности признака. С помощью порядковых
(ранговых) шкал измеряют
интенсивность оценок каких-то свойств, суждений, событий, степени согласия или несогласия с
предложенными утверждениями.
Построение порядковой шкалы можно проиллюстрировать на примере переменной «политическое
участие гражданина»1, использованием измерения, позволяющего ранжировать граждан по классам,
различающимся количеством данного свойства, а именно:
1)
отсутствие политического участия;
2)
эпизодическое или регулярное участие в выборах в качестве избирателя;
3)
регулярное участие в выборах, членство в политической партии;
4)
регулярное участие в различных политических компаниях, акциях и т.д.
5)
участие в выборах в качестве кандидата;
1
5
6)
повседневное участие в принятии политических решений.
В приведенном примере интенсивность политического участия возрастает от первого класса к
шестому. Можно утверждать, что в классе
2
(участие в выборах в качестве избирателя) признак
«политическое участие» выражен больше, чем в классе 1 (отсутствие участия), но меньше, чем в классе 5
(участие в выборах в качестве кандидата). Относя изучаемых нами граждан к определенным классам
политического участия, мы тем самым ранжируем их по данному признаку. Но такое ранжирование по
классам не дает точных показателей, как фиксированный интервал, «эталон меры» политического участия.
Поэтому по сравнению с интервальными шкалами возможности математических операций со значениями
порядковых переменных ограничены.
Порядковые измерения имеют широкое применение в социологических исследованиях. Например,
такие распространенные характеристики, как социальный статус или уровень образования измеряются по
порядковой шкале. Порядковыми по своей природе являются такие переменные, как «политическая
активность», «интерес к политике», «степень доверия к правительству», «отношение к той или иной
политической партии».
8. Подытоживание (обработка) номинальных переменных в SPSS.
Наименее полную информацию дают номинальные измерения (шкала наименований). Номинальная
шкала устанавливает отношения равенства между явлениями, которые включены в один класс. Каждый
элемент шкалы существует как бы сам по себе, и в целом шкала не упорядочена. Единственное условие
состоит в том, что все элементы должны иметь единое основание для выделения. Номинальные
переменные отражают сугубо качественные признаки, такие как «политическая ориентация», «членство в
партии»,
«тип политического режима». При помощи номинальных переменных также измеряются
преимущественно объективные признаки респондентов (пол, возраст, партийность, семейное положение,
род занятий и др.). Соответственно, числовые значения на номинальном уровне не отражают каких-либо
свойств объектов, а служат своего рода «ярлыками», «опознавательными кодами» классов.
Для номинальный и порядковых переменных с небольшим количеством категорий существует общее
название: категориальные, или неметрические.
9. Сортировка, расщепление и условный отбор данных в SPSS.
10.Создание, обработка и анализ множественных переменных в SPSS.
11. Преобразование данных (перекодирование, визуальная категоризация,
подсчет встречаемости) в SPSS.
12.Создание и редактирование графических изображений в SPSS.
Редактирование мобильных таблиц в SPSS.
13. Подытоживание (обработка) количественных переменных в SPSS.
14. Построение и анализ таблиц сопряженности в SPSS. Создание
перекрестных таблиц для переменных с множественными ответами.
15. Изучение связи между категориальными и количественными
переменными в SPSS.
16.Раскройте процедуру счета множественных ответов в excel.
Счетеслимн - функция позволяет подсчитывать ячейки в Excel, которые
удовлетворяют сразу двум и более условиям.
Чтобы подсчитать ячейки, основываясь на нескольких критериях
(например,
содержащие "green" и больше
9),
подходит функция СЧЁТЕСЛИМН

6
=СЧЁТЕСЛИМН(A1:A5;"green";B1:B5;">9")
17.В чем заключается и для чего используется процедура транспонирования
переменных в excel?
Измнение шапки таблицы -
=Трансп, fx - выделяем таблицу
Контр С, контр В, F2, Контр+Шифт+Enter
КонтрС - специальная вставка+значения - дальше заменяем контр H
и получаем то, ЧТО НУЖНО
1. Выделяются все варианты ответов всех столбцов (это может быть и две строки, и 3, и 4, в
зависимости от сложности).
2. На новом листе "вставить" => специальная вставка => траспонировать.
Это позволяет горизонтальную запись представить в вертикальном виде.
18.Раскройте порядок организации данных в excel простых ответов
респондентов.
19.Раскройте процедуру получения процентных значений ответов
респондентов на простые вопросы в excel.
Нужное число в ячейке делим на все числа и умножаем на 100
=s12/s13*100
20.Раскройте порядок организации данных в excel табличных ответов
респондентов.
21.Раскройте процедуру получения процентных значений ответов
респондентов на табличные вопросы в excel.
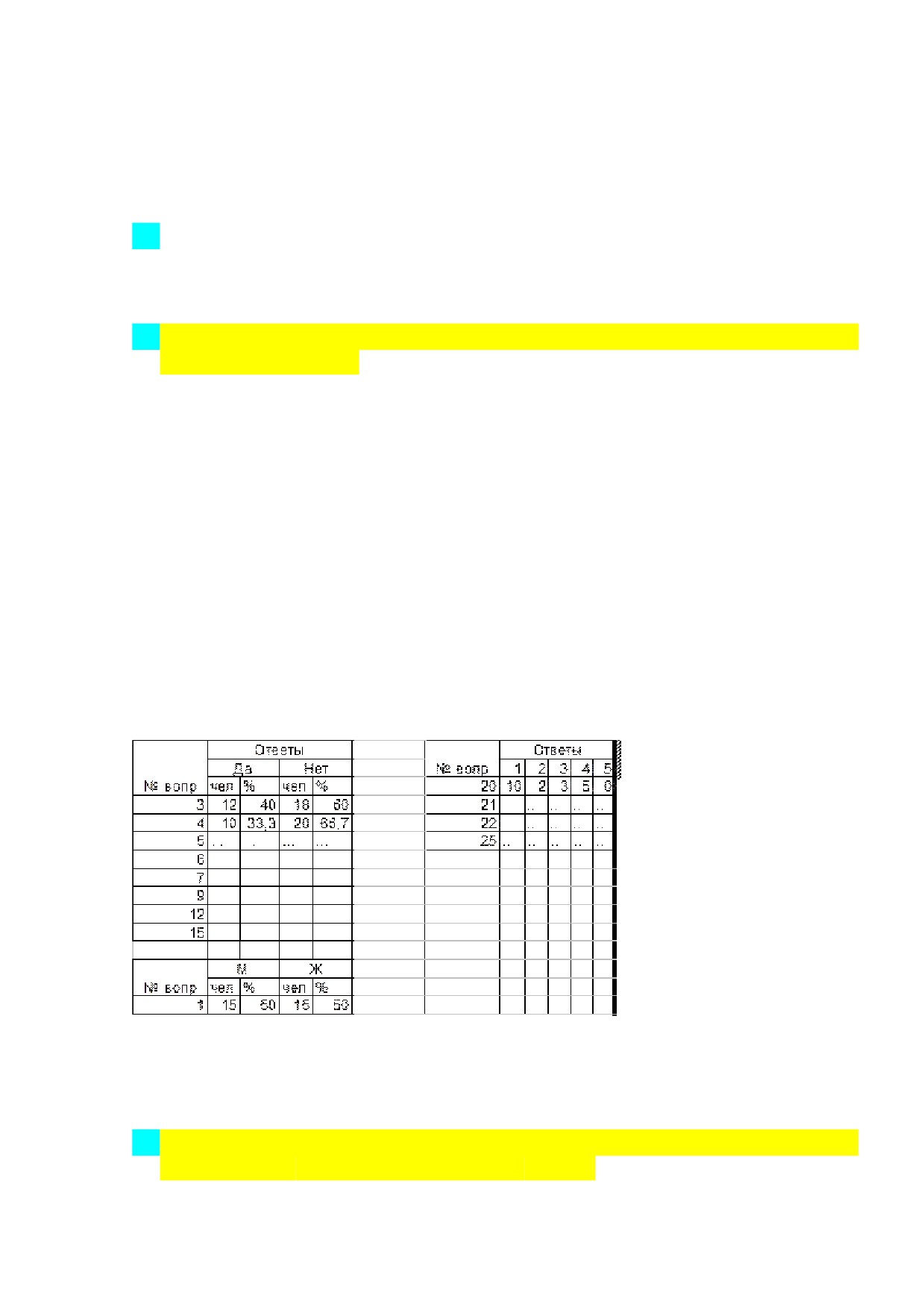
22.Раскройте порядок организации данных в excel множественных ответов
респондентов.

7
8
23.Раскройте процедуру получения процентных значений множественных
ответов респондентов в excel.
24.Раскройте порядок организации данных в excel ответов респондентов по
шкальным вопросам.
Выделить все - условное форматировнание - управление правилами -
создать правило или изменить то, что есть.
Т.е.: шкалы с Двумя альтернативными ответами: Да-Нет, Согласен-Не согласен, Нравится-
Не нравится - объединяем как «Положительный ответ (+)» и «Отрицательный ответ (-)».
Шкалы с Тремя альтернативными ответами: Да-Нет-Не знаю, Согласен-Нет-Все равно и
т.п.
Шкала 1-2-3-4-5 - отдельно.
Шкалы со специальными ответами - отдельно.
Пример:
Такую операцию (сводка - сведение данных в стат. таблицу) провести для всех вопросов
анкеты.
25.Раскройте процедуру получения процентных значений ответов
респондентов по шкальным вопросам в excel.
9
26.Раскройте процедуру создания (расчета) процентных значений ответов
респондентов в excel.
Нужную ячейку делим на Всего (СЧЕТ3) и умножаем на 100
ИЛИ
Ctrl нужная ячейка умножить на Всего и делить на 100
27.Раскройте процедуру получения пропущенных ответов респондентов в
excel.
Пропущенные значения - это пустая ячейка в записи данных. Пустая ячейка
понимается буквально, 0 - это не пустое значение.
Как правило, это систематические ошибки записи, когда количество строк не соответсвует
количеству записей.
Основные функции пропущенных значений:
1. Пропущенное значение является объектом счета;
2. Является частью количества строк, которые используют для записи;
3. Используется для определения валютности значений (достоверные данные). Как правило, это
совокупность значений всех строк (которые объединили запись), включая пропущенные значения.
Пропущенные значения рассчитываются:
1. Для всех переменных;
2. Находятся в описательных статистиках;
3. Всегда представляются в номинальных (количественных) и процентных величинах.
Пропущенные значения строятся:
1. Для переменных, где возможен один вариант ответа;
В случае excel переменные одного варианта ответа объединяются в одну переменную по
материнскому основанию. Например: переменная М, переменная Ж объединение в пол;
объединение в возраст; обьединение в место жительства... Это социально-демографические
данные.
2. Переменные множественных ответов записываются по принципу каждый ответ в отдельном
столбце
3. Расчёт номинальных значений пропущенных данных, функция счётЗ (означает, посчитать все
ячейки, которые не пустые);считать пустоты; суммеслимн
В случае Excel пустые значения определяются процедурой выборки пустых значений:
Для этого используют вставную функцию СЧИТАТЬПУСТОТЫ и функцию ЕСЛИ
=СЧИТАТЬПУСТОТЫ(диапазон, внутри которого считаются пустоты, начало и конец
диапазона отделяются:)-ЕСЛИ(диапазон, в пределах которого будет задано условие
«если»;УСЛОВИЕ как правило - это значение (цифровое) переменной, которым переменная
закодирована.)
Выборка пустых значений записывается в таблицу следующего вида: столбцы
-
1
валидные; 2 процент; 3 пропущенные; строки - это названия переменных - кол-во строк
ограничивается количеством вопросов и вариантов ответов респондентов
Строковые переменные в таблице валидности отделяются между вопросами фразами
ВСЕГО - перед вопросами (сколько всего в базе данных), ИТОГО - после вопроса (сколько всего
дали ответ)
28.Объясните порядок получения валидных значений ответов респондентов
в excel.
Валидные значения: м2 - функция - счетесли - диапазон: ф3-ф11 условие 1
10
Мз-функция - счетесли-диапазон ф3 -ф11 условие 2
М4 - функция - счёт если - диапазон G3-G11 условие 18 и тд
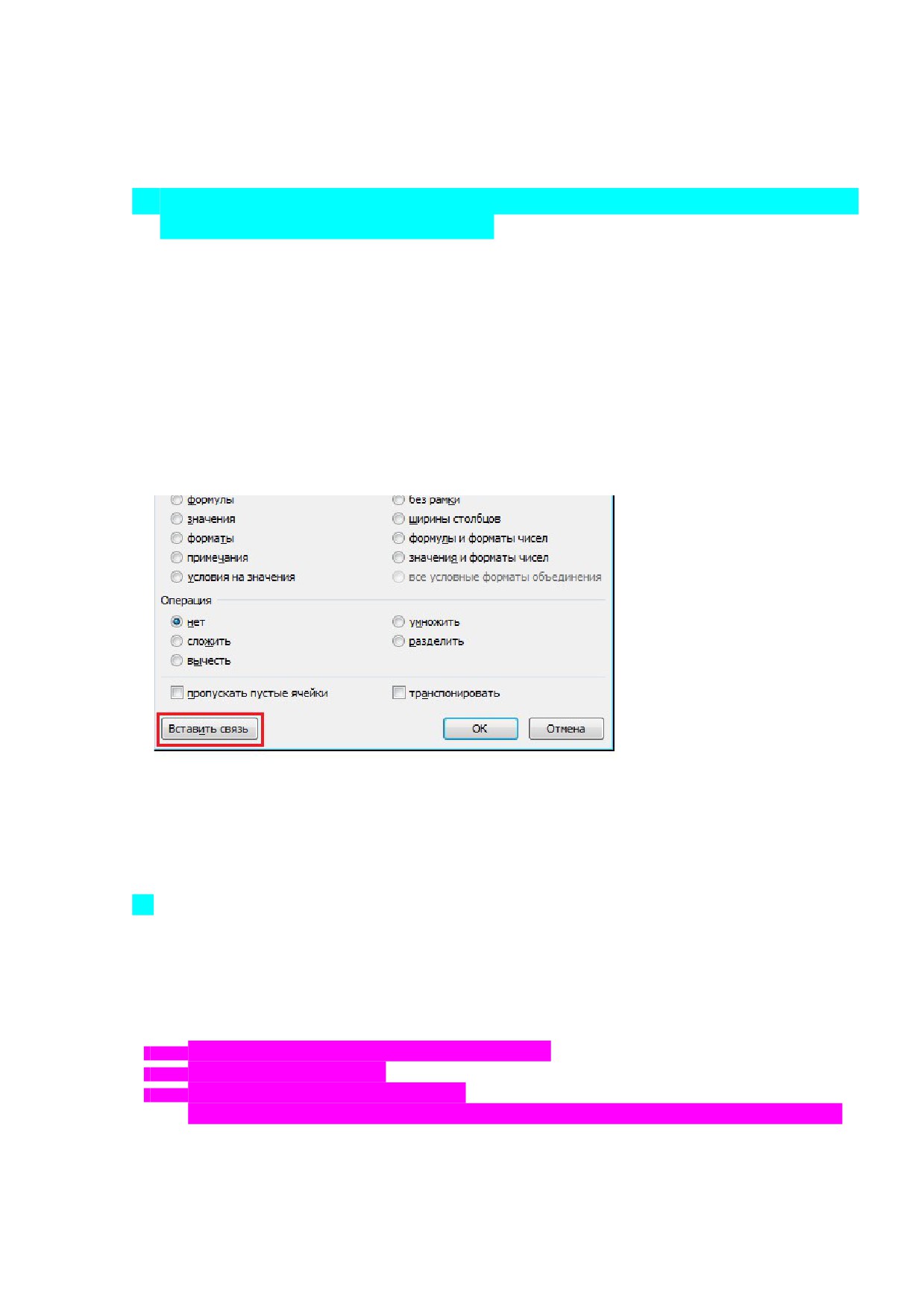
29.Раскройте условия и порядок создания сопряженных данных
(пересекающихся значений) в excel.
Связанные данные-данные, содержащие формулы, в которых присутствуют ссылки на ячейки
других таблиц (внешние ссылки).
Виды внешних ссылок:
ссылка на ячейку на другом листе (Например,=Лист2!D7);
ссылка на ячейку в другой рабочей книге (Например, [Книга2.xls]Лист2!D7).
Ctrl C (копируем ячейку), подводим курсор к тому месту, куда хотим вставить, нажимаем
правой кнопкой мыши специальная вставка - «вставить связь».
30.
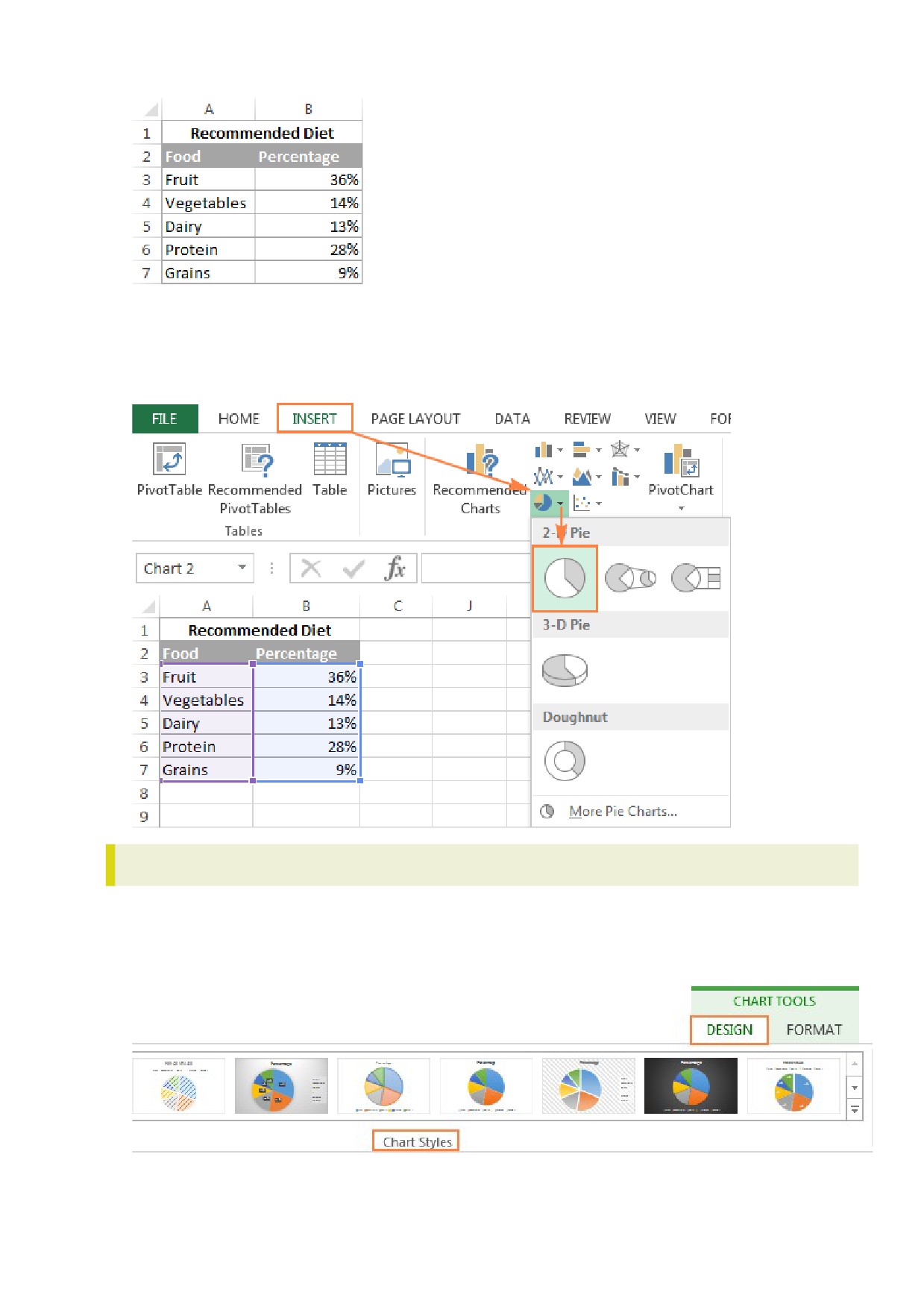
В отличии от других графиков Excel, круговые диаграммы требуют организации исходных данных
в одном столбце или в одной строке. Ведь только один ряд данных может быть построен в виде
круговой диаграммы.
Помимо этого, можно использовать столбец или строку с названиями категорий. Названия
категорий появятся в легенде круговой диаграммы и/или в подписях данных. В общем круговая
диаграмма в Excel выглядит наилучшим образом, если:
На диаграмме построен только один ряд данных.
Все значения больше нуля.
Отсутствуют пустые строки и столбцы.
Число категорий не превышает 7-9, поскольку слишком большое количество секторов
диаграммы размоет ее и воспринимать диаграмму будет очень сложно.
В качестве примера для данного руководства, попробуем построить круговую диаграмму в Excel,
опираясь на следующие данные:
11
2. ВСТАВЛЯЕМ КРУГОВУЮ ДИАГРАММУ НА ТЕКУЩИЙ РАБОЧИЙ ЛИСТ
Выделяем подготовленные данные, открываем вкладку Вставка (Insert) и выбираем подходящий
тип диаграммы (о различных типах круговых диаграмм речь пойдет чуть позже). В этом примере
мы создадим самую распространенную 2-D круговую диаграмму:
Совет: При выделении исходных данных не забудьте выбрать заголовки столбца или строки,
чтобы они автоматически появились в наименованиях вашей круговой диаграммы.
3. ВЫБИРАЕМ СТИЛЬ КРУГОВОЙ ДИАГРАММЫ (ПРИ НЕОБХОДИМОСТИ)
Когда новая круговая диаграмма появилась на рабочем листе, можно открыть
вкладку Конструктор (Design) и в разделе Стили диаграмм (Charts Styles) попробовать различные
стили круговых диаграмм, выбрав тот, который больше всего подходит для Ваших данных.
Круговая диаграмма, заданная по умолчанию (Стиль 1) в Excel 2013, выглядит на рабочем листе
следующим образом:

12
31.Раскройте порядок организации данных и создания на их основе
круговых диаграмм в excel.
Инструкция по созданию диаграммы
1.
Создаем таблицу. Я придумал небольшое производство столов и стульев,
использовав по ходу генератор случайных чисел, точнее его аналог для простых целей -
функцию
СЛЧИС.
2.
Потом
выбираем
на
вкладке
"Вставка"
нужную
диаграмму.

13
Я выбрал обычную сгруппированную, она самая первая в списке.
3.
Появится гистограмма с минимальными настройками прямо на листе.
Нам такого счастья не надо, поэтому правой кнопки мыши по диаграмме вызываем
контекстное меню
и выбираем отдельный лист.

14
4.
Переходим на лист диаграммы. Там появляются новые вкладки "Макет",
"Конструктор" и "Формат". На вкладке "Макет" мы
Ставим название диаграммы
Ставим названия осей
Добавляем таблицу данных
Делаем небольшие корректировки по легенде, области построения.
32.Раскройте порядок организации данных и создания на их основе
точечных диаграмм в excel.
1.
Скопируйте образец данных листа на чистый лист или откройте лист с данными, которые
требуется нанести на точечную диаграмму.
Копирование данных рабочего листа примера
a.
Создайте пустую книгу или лист.
b.
Выделите пример в разделе справки.
ПРИМЕЧАНИЕ : Не выделяйте заголовки строк или столбцов.
Выделение примера в справке
c.
Нажмите клавиши CTRL+C.
d.
На листе выделите ячейку A1 и нажмите клавиши CTRL+V.
1.
Выделите данные, которые следует нанести на точечную диаграмму.
2.
На вкладке Вставка в группе Диаграммы нажмите кнопку Точечная.
3.
Выберите тип Точечная с маркерами.
СОВЕТ : Чтобы увидеть название какого-либо типа диаграммы, подведите к нему указатель.
4.
Щелкните в область диаграммы.
Откроется
панель Работа
с
диаграммами с
дополнительными
вкладками Конструктор, Макет и Формат.
5.
На вкладке Конструктор в группе Стили диаграмм выберите стиль, который хотите
использовать.
15
6.
Щелкните название диаграммы и введите нужный текст.
7.
Чтобы уменьшить размер названия диаграммы, щелкните название правой кнопкой мыши
и введите нужный размер в контекстном меню в поле Размер шрифта.
8.
Щелкните в области диаграммы.
9.
На вкладке Макет в группе Подписи нажмите кнопку Названия осей и выполните действия,
описанные ниже.
a.
Чтобы добавить название горизонтальной оси, выделите пункт Название основной
горизонтальной оси и затем выберите Название под осью.
b.
Чтобы добавить название вертикальной оси, выделите пункт Название основной
вертикальной оси и затем выберите нужный тип названия вертикальной оси.
c.
Щелкните каждое из названий, введите нужный текст и нажмите клавишу ВВОД.
Для данной точечной диаграммы было задано название горизонтальной оси Суточное количество
осадков и название вертикальной оси Содержание твердых частиц.
10.
Щелкните в область построения диаграммы или выберите пункт Область построения в
списке элементов диаграммы
(вкладка Макет, группа Текущий фрагмент, поле Элементы
диаграммы).
11.
На вкладке Формат в группе Стили фигур нажмите кнопку Дополнительно и затем
выберите требуемый вариант.
12.
Щелкните в области диаграммы.
13.
На вкладке Формат в группе Стили фигур нажмите кнопку Дополнительно и затем
выберите требуемый вариант.
14.
Если нужно использовать цвета темы, отличающейся от темы по умолчанию, примененной
к книге, выполните указанные ниже действия.
a.
На вкладке Разметка страницы в группе Темы нажмите кнопку Темы.
b.
Выберите нужную тему в разделе Встроенные.
33.Раскройте порядок организации данных и создания на их основе
вертикальных и горизонтальных гистограмм в excel.
Гистограмма в Excel
- это способ построения наглядной диаграммы, отражающей
изменение нескольких видов данных за какой-то период времени.
С помощью гистограммы удобно иллюстрировать различные параметры и сравнивать их.
Построим обновляемую гистограмму, которая будет реагировать на вносимые в
таблицу изменения. Выделим весь массив вместе с шапкой и кликнем на вкладку
ВСТАВКА. Найдем так ДИАГРАММЫ - ГИСТОГРАММА и выберем самый первый тип.
Перечень практических заданий:
1. Объедините имеющиеся в папке «Электоральное исследование ВАО-
2003» файлы в одну базу данных. Проконтролируйте качество данных,
выявите и устраните ошибки ввода данных. Проанализируйте
электоральную активность избирателей (В2) в различных возрастных
группах (В8).
16
2.
БД
«ВАО». Используя процедуру расщепления и частотного
распределения определите электоральный рейтинг политических
партий (в7) на выборах в Московскую городскую думу среди мужчин и
женщин.
3.
БД
«ВАО». Используя процедуру расщепления и частотного
распределения охарактеризуйте политическую активность (в2) среди
различных возрастных групп (в8).
4.
БД
«ФОМ ТВ». Используя процедуру обработки множественных
ответов проанализируйте рейтинг ТВ каналов среди телезрителей
(В21). Определите
5 наиболее популярных ТВ каналов среди
российской телеаудитории. Сколько % телезрителей просмотрело ТВ
канал ТНТ за неделю?
5.
БД «ФОМ ТВ». Определите 3 наиболее и наименее рейтинговые
передачи (в.50.1 - в 50.19) среди телеаудитории младше 30 лет и
старше 50 лет.
6.
БД «ФОМ ТВ». Определите рейтинг ТВ передач (в 50_1 - 50_20) среди
мужчин и женщин. Какие значимые отличия
(более
20%) в ТВ-
предпочтениях мужчин и женщин Вы можете выделить?
7.
БД «ФОМ ТВ». Определите долю телезрителей, интересующихся
остросюжетными фильмами (в.50.11) среди молодежи (младше 30 лет)
и людей старше 50 лет.
8.
БД «ФОМ ТВ». Определите динамику просмотра населением РФ ТВ в
течении суток в выходные дни (в.20.1 - в.20.24). Выделите 4 часа
наиболее рейтингового времени для размещения рекламы в выходной
день.
9.
БД «Bank».
По переменным Начальная зарплата и Зарплата в настоящее
время охарактеризуйте динамику средней заработной платы
сотрудников банка.
Определите разницу в доходах между
10% наименее
оплачиваемыми и 10% наиболее оплачиваемыми сотрудниками
банка по переменной Зарплата.
Определите, насколько доход
5% наиболее оплачиваемых
сотрудников отличается от среднего значения заработной платы
сотрудников банка.
Определите разницу средней заработной платы между
сотрудниками мужского и женского пола.
10.БД
«ВАО». Используя таблицы сопряженности охарактеризуйте
электоральный предпочтения (в7) в различных возрастных группах.
11.БД
«ВАО». Используя таблицы сопряженности охарактеризуйте
гендерную и возрастную структуры электората ЛДПР и КПРФ.
12.БД
«ВАО». Используя таблицы сопряженности определите, как
распределяется электорат Метельского по районам ВАО?
17
13.БД «Bank». Используя переменную «Зарплата» сравните средний
доход сотрудников:
мужского и женского пола
различных национальных групп.
14.БД
«Bank». Используя переменную
«Начальная зарплата» и
«Зарплата» определите у какой группы сотрудников (национальность,
категория) наблюдается наибольшая динамика заработной платы.
15.БД
«Bank». Используя переменную
«Начальная зарплата» и
«Зарплата» определите у какой группы сотрудников (национальность,
категория) наблюдается наибольшая динамика заработной платы.

18
16.Объясните организацию данных, которая показана на рисунке.

19
17.Объясните два случая организации данных социально-
демографических переменных, которые показаны на скрин-шоте.
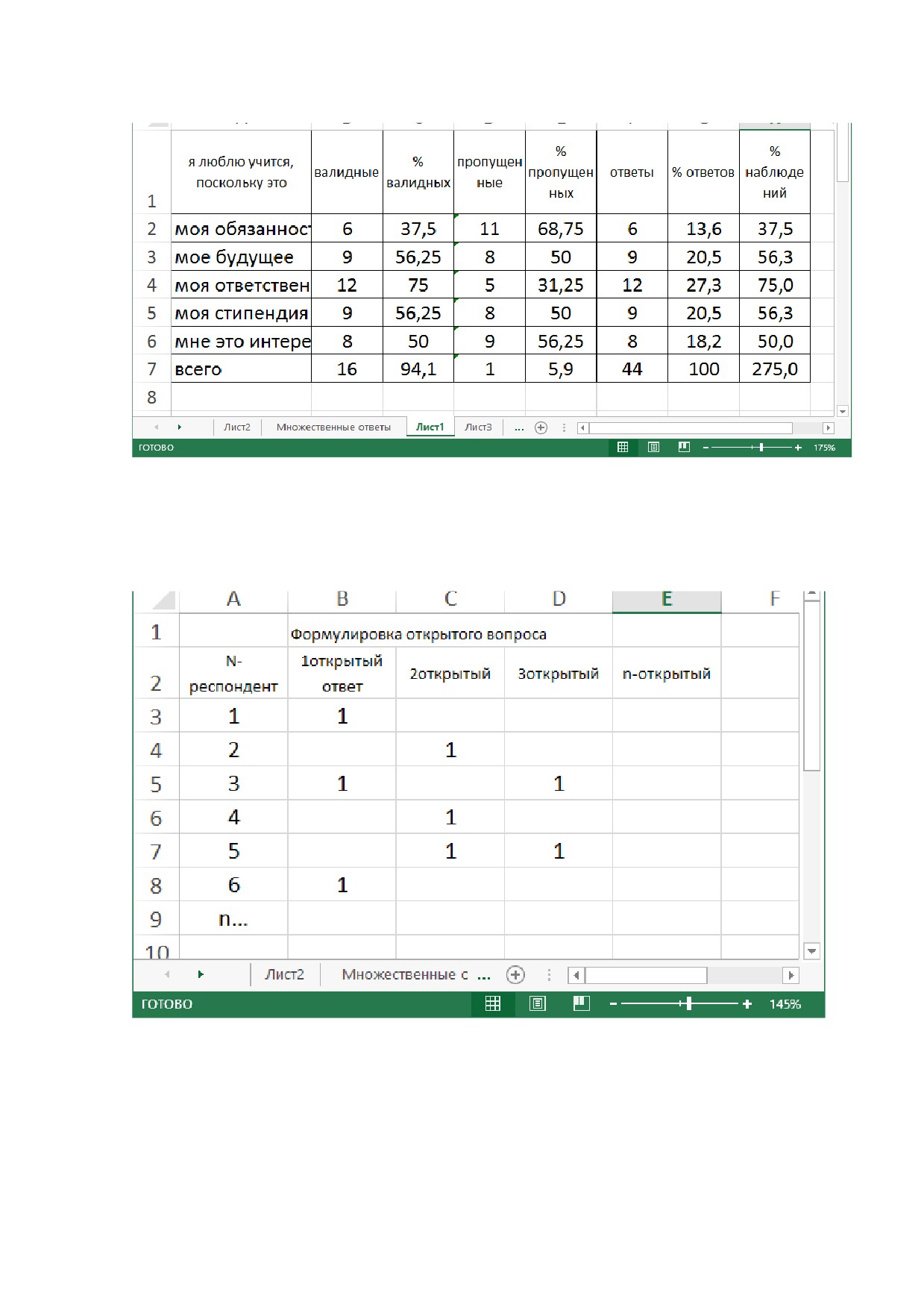
20
18.Объясните значения результатов множественных ответов
19.Объясните организацию данных открытых вопросов и ответов.

21
20.Объясните организацию данных множественных ответов.
21.Постройте любой набор данных в excel и на этой основе создайте
итожащую таблицу результатов обработки данных с номинальными и
процентными значениями.
22.В excel покажите пример использования функции «суммеслимн» для
выборки значений из базы данных.
23.В excel покажите пример использования функции «счётеслимн» для
выборки значений из базы данных.
24.Покажите пример создания таблицы пересечения данных (таблицы
сопряженности) в excel.
25.В excel создайте два условия с данными, при которых целесообразно
применять функции «счётеслимн» и «суммеслимн».
26.Покажите пример выборки данных и их обозначения (выделения) с
помощью функции условного форматирования в excel.
27.Постройте условия с данными простых вопросов, при которых будет
возможным определить валидные и пропущенные значения ответов
респондентов.
28.Постройте условия с данными вопросов, при которых будет
возможным определить валидные и пропущенные значения
множественных ответов респондентов.
29.Объясните функции расчета пропущенных и валидных значений
множественных ответов респондентов выделенных вертикальных
столбцов, которые показаны на скрин-шоте листа исходных данных и
листа расчетных данных.

22
Лист исходных данных
Лист расчетных данных
30.Объясните действие функций расчета количественных значений по
столбцу «мужской» и по столбцу «женский», сопоставляя действие
функций с двумя листами исходных и расчетных данных, которые
показаны на скрин-шотах.
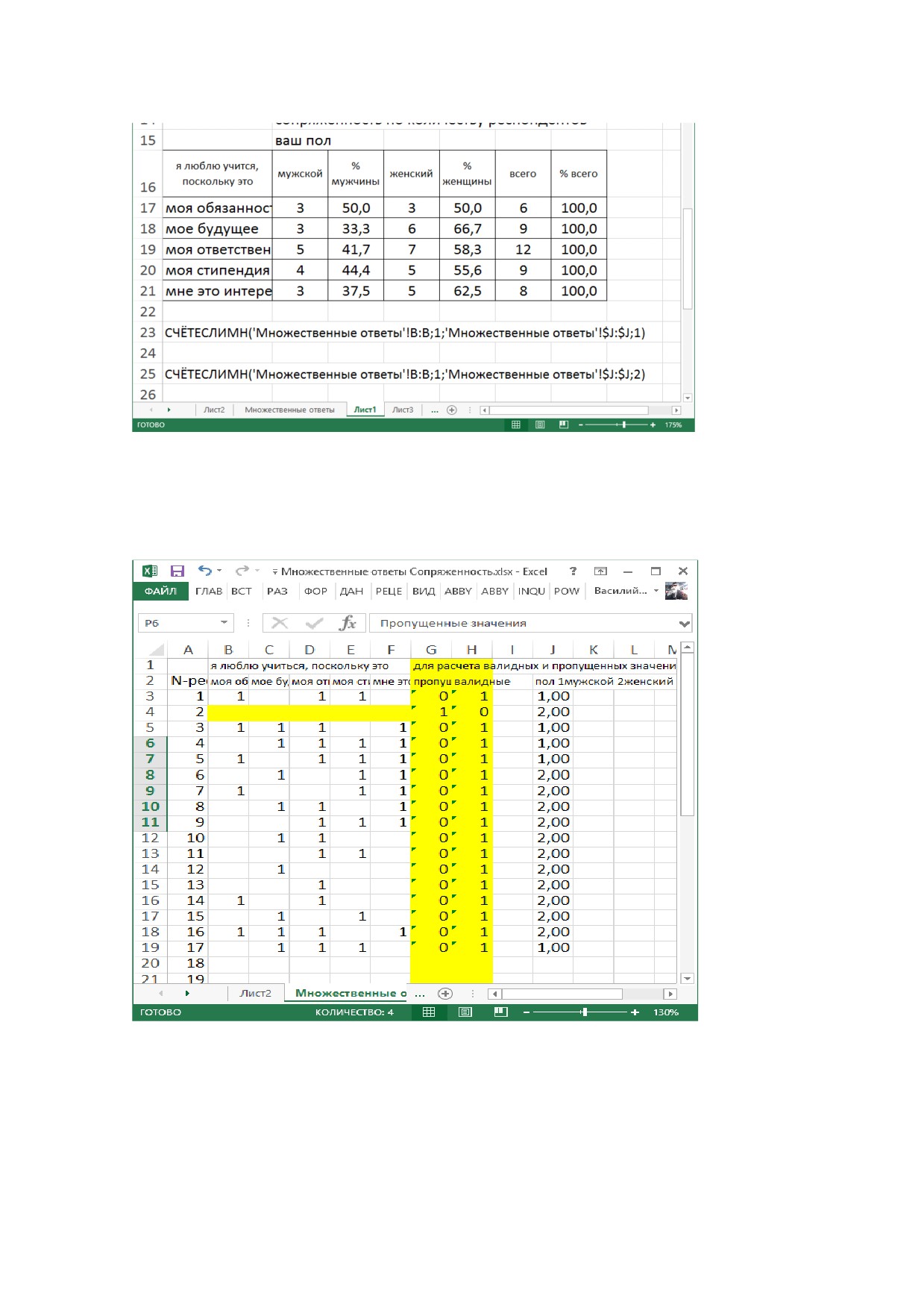
23
Лист расчетных данных
Лист исходных данных
Заведующий кафедрой социологии ИМО и СПН